

🦿 使用 RL 训练运动策略#
Genesis 支持并行仿真,非常适合高效地训练强化学习(RL)运动策略。在本教程中,我们将通过一个完整的训练示例,介绍如何获得一个基本的运动策略,使 Unitree Go2 机器人能够行走。
这是一个简单且最小的示例,演示了 Genesis 中非常基础的 RL 训练流程,通过以下示例,您将能够快速获得一个可部署到真实机器人的四足运动策略。
注意:这不是一个全面的运动策略训练流程。它使用简化的奖励项来让您轻松入门,并且没有利用 Genesis 在大批量上的速度优势,因此它仅用于基本演示目的。
致谢:本教程的灵感来源于 Legged Gym 并借鉴了其几个核心概念。
环境概述#
我们首先创建一个 gym 风格的环境(go2-env)。
初始化#
__init__ 函数通过以下步骤设置仿真环境:
控制频率。 仿真以 50 Hz 运行,与真实机器人的控制频率相匹配。为了进一步缩小 sim2real 差距,我们还手动仿真了真实机器人上显示的动作延迟(约 20ms,一个 dt)。
场景创建。 创建仿真场景,包括机器人和一个静态平面。
PD 控制器设置。 首先根据名称识别电机。然后为每个电机设置刚度和阻尼。
奖励注册。 奖励函数在配置中定义并注册以指导策略。这些函数将在”奖励”部分中解释。
缓冲区初始化。 初始化缓冲区以存储环境状态、观测值和奖励。
重置#
reset_idx 函数重置指定环境的初始姿态和状态缓冲区。这确保机器人从预定义配置开始,这对于一致的训练至关重要。
步骤#
step 函数执行动作并返回新的观测值和奖励。其工作原理如下:
动作执行。 输入动作将被裁剪、重新缩放,并叠加在默认电机位置之上。转换后的动作代表目标关节位置,然后将发送到机器人控制器进行单步执行。
状态更新。 检索机器人状态(如关节位置和速度)并存储在缓冲区中。
终止检查。 如果 (1) 回合长度超过允许的最大值 (2) 机器人身体方向显著偏离,则环境终止。终止的环境会自动重置。
奖励计算。
观测计算。 用于训练的观测值包括基座角速度、投影重力、命令、自由度位置、自由度速度以及先前动作。
奖励#
奖励函数对于策略指导至关重要。在此示例中,我们使用:
tracking_lin_vel: 跟踪线速度命令(xy 轴)
tracking_ang_vel: 跟踪角速度命令(偏航)
lin_vel_z: 惩罚 z 轴基座线速度
action_rate: 惩罚动作的变化
base_height: 惩罚基座高度偏离目标值
similar_to_default: 鼓励机器人姿态与默认姿态相似
训练#
在这个阶段,我们已经定义了环境。现在,我们使用 rsl-rl 的 PPO 实现来训练策略。首先,通过 pip 安装所有 Python 依赖项:
pip install tensorboard "rsl-rl-lib>=5.0.0"
安装后,通过运行以下命令开始训练:
python examples/locomotion/go2_train.py
要监控训练过程,启动 TensorBoard:
tensorboard --logdir logs
您应该看到类似这样的训练曲线:
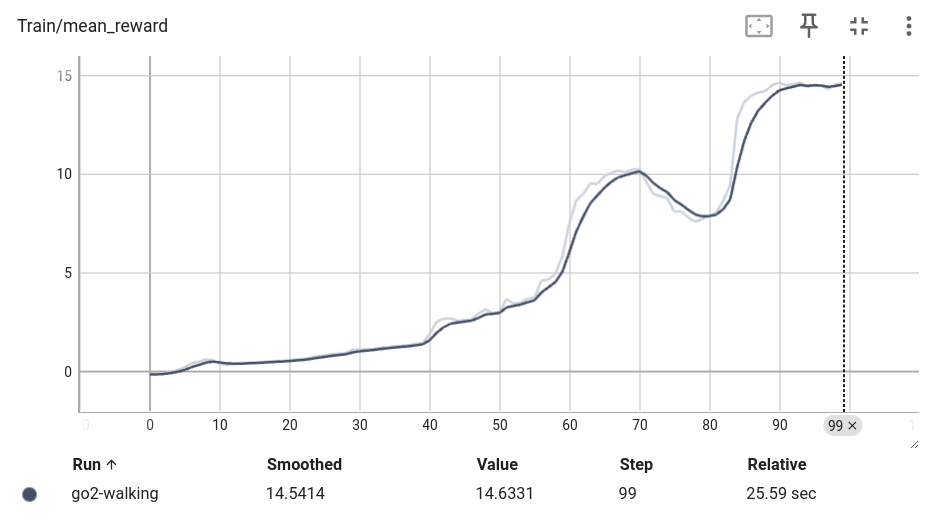
评估#
最后,让我们推出训练好的策略。运行以下命令:
python examples/locomotion/go2_eval.py
您应该看到类似这样的 GUI:
如果您身边恰好有一台真实的 Unitree Go2 机器人,您可以尝试部署该策略。玩得开心!